Privacidade por padrão contra o capitalismo de vigilância
I. Informação é poder
O modelo de negócios da maioria das empresas de internet hoje é simplesmente baseado em combinar as preferências do usuário com anúncios em seus serviços. Grandes empresas “de inovação” que resumem todo seu aparato tecnológico no mais básico instrumento capitalista: a publicidade.

Para que isso ocorra, essas corporações vêm criando métodos de coleta de todos os rastros digitais deixados pelos usuários. Absolutamente tudo pode ser usado: Logs da conexão, tamanho da tela, tipo de dispositivo, análise textual de emails privados, locais onde esteve através do do GPS e até os movimentos que você faz com o mouse durante a nossa navegação.
Essa coleta tem sido feita e aperfeiçoada aliando conhecimento da área de ciência de dados, machine learning e inteligência artificial, e usada muitas vezes de forma não ética e até criminosa.
Tanto poder trouxe lucros bilionários para as companhias de tecnologia, especialmente as que lidam com uma grande massa de usuários e seus dados. No ranking de empresas mais valiosas do mundo, onde antes tínhamos conglomerados como Exxon, General Eletric e Walmart, hoje vemos Apple, Facebook, Amazon entre outras. Novos tempos onde, comumente se diz, os dados são o novo petróleo.
Tais impactos dessa financeirização radical dos dados pelo capitalismo neoliberal, sentidos desde a vida cotidiana dos usuários até no mercado de ações global, levou a professora de Harvard, Shoshana Zuboff, a popularizar o termo capitalismo de vigilância.
II. Desidentificação não é o bastante
Sabemos a importância dos dados, base da pesquisa científica moderna que nos ajudam a entender a natureza e a sociedade. Na academia, institutos e centros de pesquisas, assegura-se a ética científica e um princípio simples é: os dados devem passar por um processo de desidentificação, a partir de processos como anonimização, pseudo-anonimização, re-identificação etc.
Novas leis e regulamentações estão sendo criadas. Mark Zuckerberg, por exemplo, tem enfrentado duras sabatinas no congresso estadunidense em iniciativas que querem entender tais coletas e proteger a privacidade dos usuários. A maioria delas baseia-se em garantir essa desidentificação, para que qualquer tipo de informação esteja completamente desconectada com a identidade dos indíviduos.
O problema é que não existem modelos únicos de desidentificação. Mesmo seguindo bons métodos em seus trabalhos de pesquisa públicos, pouco pode-se garantir sobre as pesquisas internas dessas grandes empresas de tecnologia.
Protegidas por segredos comerciais e sem um claro padrão de anonimização, as ações com a montanha de dados coletados fica extremamente nebulosa. Os peta bytes de informações são tantos que acabam vazando pelas beiradas, como em vazamentos de ataques crackers, por funcionários mal intencionados, ou, não intencionalmente, por meio de parceiros de negócios e serviços de terceiros.
Pouco se pode garantir, mas muito é sabido como o Facebook fez experimentos com o sentimento de seus usuários; tratou de forma negligente os dados pessoais de seus usuários e, por meio de ferramentas para serviços externos, potencialmente influenciou na democracia de grande países - vide o escâdalo de dados da Cambridge Analytica.
Enquanto são discutidas soluções legais para estes problemas, outro tipo de solução seria uma reestruturação técnica de como as redes sociais e plataformas onlines funcionam, coletam e usam os dados dos usuários. Garantindo a privacidade dos usuários por padrão, desde o núcleo de suas aplicações.
III. Uma solução técnica: plataforma caixa-preta
Plataforma Social Segura
Uma arquitetura com esse objetivo é apresentada no artigo em que sou coautor Privacy-preserving recommendations for Online Social Networks using Trusted Execution Environments (Recomendações com privacidade preservada para Redes Sociais Online usando Ambientes de Execução Segura, tradução livre).
O que propomos é basicamente uma plataforma com privacidade por padrão, chamada Plataforma Social Segura (SSP). A SSP cobriria genericamente as funcionalidades críticas de redes sociais online, como a administração de contas de usuários e os sistemas de recomendação de conteúdo e anúncios - parte vital do funcionamento e do modelo de negócios dessas redes.
Provedores de aplicações sociais online seriam, então, capazes de baixar e instalar a plataforma em seus próprios servidores e administrar sua performance como necessário. Dessa forma poderá configurar a plataforma para se adequar a seus serviços, configurando esquemas de conteúdo e parceiros de publicidade.
Os provedores também poderiam construir o front-end de seus aplicativos com qualquer tecnologia que desejarem. No entanto, em nenhum momento deste processo o provedor tem acesso aos dados dos usuários.
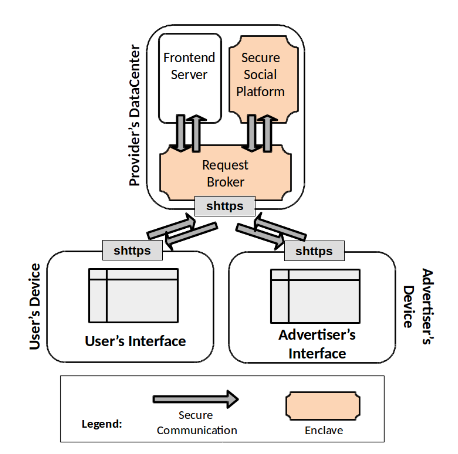
Além disso, a SSP empregaria o uso de tecnologias de segurança baseada em hardware. As informações dos usuários, além de serem criptografadas para o armazenamento, seriam também processadas em regiões criptografadas da memória (enclaves), o que ofecere um nível de segurança até para ataques físicos nos servidores da aplicação.
Assim, a SSP é efetivamente uma caixa-preta na perspectiva dos provedores de serviço, sem deixar que estes ofereçam conteúdo personalizado e anúncios corretos de acordo com a preferência de seus usuários.
Protótipo
Seguindo a arquitetura proposta, implementamos um protótipo da nossa SSP. A partir de uma API construída, foram inseridas as informações de nossos supostos usuários sobre seus gostos a respeito de filmes. Fizemos isso para dois conjuntos de dados: de 100 mil avaliações e de 1 milhão de avaliações.
Nosso objetivo foi avaliar a aplicabilidade da nossa arquitetura em um sistema de recomendação de obras audiovisuais, onde, a partir do seu gosto atual de filmes, indicaríamos quias outros filmes os usuários deveriam assistir.
Com essas informações “coletadas”, avaliamos o tempo de execução da API para treinar os dados e construir as predições usando oito algoritmos diferentes de predição. Foram usados servidores com especificação técnica similar ao que é frequentemente usado comercialmente. Para o conjunto de dados de 100 mil avaliações, tivemos tempo de processamento entre pouco mais de um minuto e aproximandamento 24 minutos. Já para o conjunto de dados de 1 milhão de avaliações, os tempos foram de 30 minutos até quase 7 horas em algoritmos mais sofisticados.
Conclusão da nossa abordagem
Os resultados mostraram que há aplicabilidade dessa arquitetura, principalmente em pequenas e médias redes sociais, onde a penalidade em performance é razoável dadas as melhorias de segurança e privacidade. Com o aprimoramento das tecnologias e o aperfeiçoamento da arquitura proposta, esperamos que esse tipo de abordagem exerça um papel importante em proteger os dados dos usuários nas novas redes online.
IV. Conclusão do papo todo
Junto às crescentes alternativas técnicas, medidas legais e ativismos pelos direitos digitais que surgem, podemos talvez construir e alcançar plataformas na rede mais justas, onde o usuário não seja uma mercadoria, seus sentimentos não sejam commodities e as relações sociais digitais não signifiquem apenas lucro.
Mais importante ainda que as tecnicidades de segurança ou privacidade, deveríamos apoiar plataformas, sites, redes e cooperativas que trabalhem não só contra a vigilância em si, mas também contra seu agente.
No combate ao capitalismo de vigilância, melhor que plataformas anti-vigilância, claro, são plataformas anticapitalistas.
– Guilmour